今天來利用RNN的LSTM訓練模型,來預測股票吧!
我們以元大50 2022年1-12月的收盤價作為訓練資料。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense
from plotly.graph_objs import Scatter, Layout
from plotly.offline import plot
定義train與test資料
def load_data(df, sequence_length=10, split=0.8): #載入時間序列資料
data_all = np.array(df).astype(float) # 轉為浮點數據
scaler = MinMaxScaler()
data_all = scaler.fit_transform(data_all) # 將數據縮放為 0~1 之間
data = []
for i in range(len(data_all) - sequence_length - 1):
# 每筆 data 資料有 11 欄
data.append(data_all[i: i + sequence_length + 1])
reshaped_data = np.array(data).astype('float64')
x = reshaped_data[:, :-1] # 第 1至第10個欄位為 特徵
y = reshaped_data[:, -1] # 第 11個欄位為 label
split_boundary = int(reshaped_data.shape[0] * split)
train_x = x[: split_boundary] # 前 80% 為 train 的特徵
test_x = x[split_boundary:] # 最後 20% 為 test 的特徵
train_y = y[: split_boundary] # 前 80% 為 train 的 label
test_y = y[split_boundary:] # 最後 20% 為 test 的 label
return train_x, train_y, test_x, test_y, scaler
建立一個循環神經網絡
def build_model():
model = Sequential()
# 隱藏層:256 個神經元,input_shape:(10,1)
# TIME_STEPS=10,INPUT_SIZE=1
model.add(LSTM(input_shape=(10,1),units=256,unroll=False))
model.add(Dense(units=1)) # 輸出層:1 個神經元
#compile:loss, optimizer, metrics
model.compile(loss="mse", optimizer="adam", metrics=['accuracy'])
return model
進行預測
def train_model(train_x, train_y, test_x, test_y):
model = build_model()
try:
model.fit(train_x, train_y, batch_size=100, epochs=300, validation_split=0.1)
predict = model.predict(test_x)
predict = np.reshape(predict, (predict.size, )) #轉換為1維矩陣
except KeyboardInterrupt:
print(predict)
print(test_y)
return predict, test_y #傳回 預測值和真實值
讀取檔案
pd.options.mode.chained_assignment = None #取消顯示pandas資料重設警告
filename = 'twstockyear2022.csv'
df = pd.read_csv(filename, encoding='big5') #以pandas讀取檔案
ddprice=pd.DataFrame(df['收盤價'])
模型訓練和預測,並還原預測結果和真實資料的數值範圍
train_x, train_y, test_x, test_y, scaler =load_data(ddprice, sequence_length=10, split=0.8)
predict_y, test_y = train_model(train_x, train_y, test_x, test_y)
predict_y = scaler.inverse_transform([[i] for i in predict_y]) # 還原
test_y = scaler.inverse_transform(test_y) # 還原
將預測結果和真實資料可視化為一個散點圖
plt.plot(predict_y, 'y:') #預測
plt.plot(test_y, 'g-') #收盤價
plt.legend(['predict', 'price'])
plt.show()
dd2=pd.DataFrame({"predict":list(predict_y),"label":list(test_y)})
#轉換為 numpy 陣列,並轉為 float
dd2["predict"] = np.array(dd2["predict"]).astype('float64')
dd2["label"] = np.array(dd2["label"]).astype('float64')
data = [
Scatter(y=dd2["predict"],name='預測'),
Scatter(y=dd2["label"],name='收盤價')
]
plot({"data": data, "layout": Layout(title='2022年個股預測圖')},auto_open=True)
結果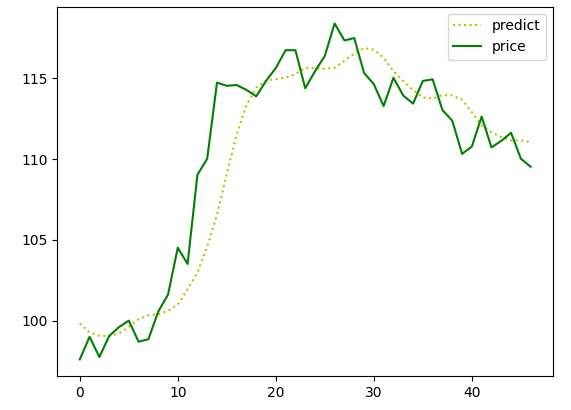
---20231010---


 iThome鐵人賽
iThome鐵人賽